
node结点
第1题:
以下程序中函数fun的功能是:构成一个如图所示的带头结点的单词链表,在结点的数据域中放入了具有两个字符的字符串。函数disp的功能是显示输出该单链表中所有结点中的字符串。请填空完成函数disp。[*]
include<stdio.h>
typedef struct node /*链表结点结构*/
{char sub[3];
struct node *next;
}Node;
Node fun(char s) /*建立链表*/
{ … }
void disp(Node *h)
{ Node *
第2题:
函数min()的功能是:在带头结点的单链表中查找数据域中值最小的结点。请填空
include <stdio.h>
struct node
{ int data;
struct node *next;
};
int min(struct node *first)/*指针first为链表头指针*/
{ struct node *p; int m;
p=first->next; re=p->data; p=p->next;
for( ;p!=NULL;p=【 】)
if(p->data<m ) re=p->data;
return m;
}
第3题:
typedef int datatype; //结点的数据类型,假设为int
typedef struct NODE *pointer; //结点指针类型
struct NODE {
datatype data;
pointer lchild,rchild;
};
typedef pointer bitree; //根指针类型
答案: void moves(sqlist *L) { int i,j; datatype x; i=1;j=L->n; while(i< j) { while(L->data[i]< 0 && i< j) i++; while(L->data[j]>=0 && i< j) j--; if(i< j) { x=L->data[i];L->data[i]=L->data[j];L->data[j]=x; i++;j--; } } }
第4题:
下列给定程序中,是建立一个带头结点的单向链表,并用随机函数为各结点数据域赋值。函数fun的作用是求出单向链表结点(不包括头结点)数据域中的最大值,并且作为函数值返回。
请改正程序指定部位的错误,使它能得到正确结果。
[注意] 不要改动main函数,不得增行或删行,也不得更改程序的结构。
[试题源程序]
include<stdio.h>
include<stdlib.h>
typedef struct aa
{
int data;
struct aa *next;
}NODE;
fun(NODE *h)
{
int max=-1;
NODE *p;
/***********found************/
p=h;
while(p)
{
if(p->data>max)
max=p->data;
/************found************/
p=h->next;
}
return max;
}
outresult(int s, FILE *Pf)
{
fprintf(pf, "\nThe max in link: %d\n", s);
}
NODE *creatlink(int n, int m)
{
NODE *h, *p, *s, *q;
int i, x;
h=p=(NODE *)malloc(sizeof(NODE));
h->data=9999;
for(i=1; i<=n; i++)
{
s=(NODE *)malloc(sizeof(NODE));
s->data=rand()%m; s->next=p->next;
p->next=s; p=p->next;
}
p->next=NULL;
return h;
}
outlink(NODE *h, FILE *pf)
{
NODE *p;
p=h->next;
fprintf(Pf, "\nTHE LIST:\n\n HEAD");
while(P)
{
fprintf(pf, "->%d", P->datA); p=p->next;
}
fprintf(pf, "\n");
}
main()
{
NODE *head; int m;
head=cteatlink(12,100);
outlink(head, stdout);
m=fun(head);
printf("\nTHE RESULT"\n");
outresult(m, stdout);
}
第5题:
阅读以下说明和C语言函数,将应填入(n)。
【说明】
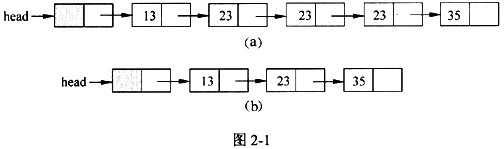
已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数 compress(NODE*head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。
图2-1(a)、(b)是经函数compress()处理前后的链表结构示例图。
链表的结点类型定义如下:
typedef struct Node{
int data;
struct Node *next;
}NODE;
【C语言函数】
void compress(NODE *head)
{ NODE *ptr,*q;
ptr= (1); /*取得第一个元素结点的指针*/
while( (2)&& ptr->next) {
q=ptr->next;
while(q&&(3)) { /*处理重复元素*/
(4)q->next;
free(q);
q=ptr->next;
}
(5) ptr->next;
}/*end of while */
}/*end of compress*/
第6题:
在C语言中,可以用typedef声明新的类型名来代替已有的类型名,比如有学生链表结点: typedef struct node{ int data; struct node * link; }NODE, * LinkList; 下述说法正确的是______。
A.NODE是结构体struct node的别名
B.* LinkList也是结构体struct node的别名
C.LinkList也是结构体struct node的别名
D.LinkList等价于node*
第7题:
阅读以下说明和C语言函数,将应填入(n)处的字句写在对应栏内。
【说明】
函数sort (NODE *head)的功能是;用冒泡排序法对单链表中的元素进行非递减排序。对于两个相邻结点中的元素,若较小的元素在前面,则交换这两个结点中的元素值。其中,head指向链表的头结点。排序时,为了避免每趟都扫描到链表的尾结点,设置一个指针endptr,使其指向下趟扫描需要到达的最后一个结点。例如,对于图4-1(a)的链表进行一趟冒泡排序后,得到图4-1(b)所示的链表。

链表的结点类型定义如下:
typedef struct Node {
int data;
struct Node *next;
} NODE;
【C语言函数】
void sort (NODE *head)
{ NODE *ptr,*preptr, *endptr;
int tempdata;
ptr = head -> next;
while ((1)) /*查找表尾结点*/
ptr = ptr -> next;
endptr = ptr; /*令endptr指向表尾结点*/
ptr =(2);
while(ptr != endptr) {
while((3)) {
if (ptr->data > ptr->next->data){
tempdata = ptr->data; /*交换相邻结点的数据*/
ptr->data = ptr->next->data;
ptr->next->data = tempdata;
}
preptr =(4); ptr = ptr -> next;
}
endptr =(5); ptr = head->next;
}
}
第8题:
以下程序的功能是:建立一个带布头结点的单向链表,并将存储在数组中的字符依次存储到链表的各个结点中,请从与下划线处号码对应的一组选项中选择出正确的选项
#include <stdlib.h>
struct node
{char data; struct node *next;};
(48) CreatList(char*s),
{struct node *h,*p,*q;
h=(struct node*)malloc(sizeof(struct node));
p=q=h;
while(*s!="\0")
{ p=(struct node*)malloc(sizeof(struct node));
p->data= (49) ;
q->next=p;
q= (50) ;
s++;
}
p->next="\0";
return h;
}
main()
{ char str[]="link list";
struct node*head;
head=CreatList(str);
…
}
(1)
A.char*
B.struct node
C.struct node*
D.char
第9题:
链表题:一个链表的结点结构
struct Node
{
int data ;
Node *next ;
};
typedef struct Node Node ;
(1)已知链表的头结点head,写一个函数把这个链表
逆序( Intel)
第10题:
阅读以下说明,Java代码将应填入(n)处的字句写在对应栏内。
【说明】
链表和栈对象的共同特征是:在数据上执行的操作与在每个对象中实体存储的基本类型无关。例如,一个栈存储实体后,只要保证最后存储的项最先用,最先存储的项最后用,则栈的操作可以从链表的操作中派生得到。程序6-1实现了链表的操作,程序6-2实现了栈操作。
import java.io.*;
class Node //定义结点
{ private String m_content;
private Node m_next;
Node(String str)
{ m_content=str;
m_next=null; }
Node(String str,Node next)
{ m_content=str;
m_next=next; }
String getData() //获取结点数据域
{ return m_content;}
void setNext(Node next] //设置下一个结点值
{ m_next=next; }
Node getNext() //返回下一个结点
{ return m_next; )
}
【程序6-1】
class List
{ Node Head;
List()
{ Head=null; }
void insert(String str) //将数据str的结点插入在整个链表前面
{ if(Head==null)
Head=new Node(str);
else
(1)
}
void append(String str) //将数据str的结点插入在整个链表尾部
{ Node tempnode=Head;
it(tempnode==null)
Heed=new Node(str);
else
{ white(tempnode.getNext()!=null)
(2)
(3) }
}
String get() //移出链表第一个结点,并返回该结点的数据域
{ Srting temp=new String();
if(Head==null)
{ System.out.println("Errow! from empty list!")
System.exit(0); }
else
{ temp=Head.getData();
(4) }
return temp;
}
}
【程序6-2】
class Stack extends List
{ void push(String str) //进栈
{ (5) }
String pop() //出栈
{ return get();}
}