

第1题:
A、编码方案为CS1和CS2的数据业务
B、编码方案为CS3和CS4的数据业务
C、调制编码方案为MCS1~MCS4的数据业务
D、调制编码方案为MCS5~MCS9的数据业务
第2题:
●下图所示的两种调制方法分别是(20)。

(20)
A.(a)调幅(b)调相
B.(a)调频(b)调相
C.(a)调幅(b)调频
D.(a)调频(b)调幅
第3题:
A.错误
B.正确
第4题:
什么是逻辑数据?
(2)逻辑数据与数值的区别是什么?
(3)汉字的编码方案有几种?说明其原理。
第5题:
下图表示了某个数据的两种编码,这两种编码分别是( ),该数据是( )。
A.X为差分曼彻斯特码,Y为曼彻斯特码
B.X为差分曼彻斯特码,Y为双极性码
C.x为曼彻斯特码,Y为差分曼彻斯特码
D.X为曼彻斯特码,Y为不归零码
第6题:
下图的两种编码方案分别是(19)。

A.①曼彻斯特编码,②双相码
B.①RZ编码,②曼彻斯特编码
C.①NRZ-I编码,②差分曼彻斯特编码
D.①极性码,②双极性码
第7题:
下图为DARPA提出的公共入侵检测框架示意图,该系统由4个模块组成。其中模块①~④分别是什么。

(1)响应单元
(2)事件分析器
(3)事件数据库
(4)事件产生器
第8题:
下图的两种编码方案分别是(13)。
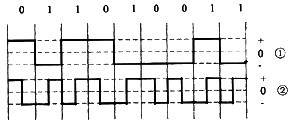
A.①差分曼彻斯特编码,②双相码
B.①m(2编码,②差分曼彻斯特编码
C.ONRZ-I编码,②曼彻斯特编码
D.①极性码,②双极性码
第9题:
● 下图表示了某个数据的两种编码,这两种编码分别是 (15) ,该数据是 (16)
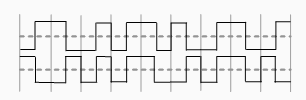
(15)
A. X为差分曼彻斯特码,Y为曼彻斯特码
B. X为差分曼彻斯特码,Y为双极性码
C. X为曼彻斯特码,Y为差分曼彻斯特码
D. X为曼彻斯特码,Y为不归零码
(16)
A. 010011110
B. 010011010
C. 011011010
D. 010010010
第10题:
A、顺序编码
B、重复编码
C、组合编码
D、成组编码