
第1题:
消息摘要算法MD5(Message Digest)是一种常用的Hash函数。MD5算法以一个任意长的数据块作为输入,其输出为一个______比特的消息摘要。
A.128
B.160
C.256
D.512
第2题:
常见的摘要算法有消息摘要4算法MD4、消息摘要5算法MD5和__________。
第3题:
A、对称加密算法
B、非对称加密算法
C、数字摘要算法
D、Hash算法
第4题:
● 使用 SMTP 协议发送邮件时,可以选用 PGP 加密机制。PGP 的主要加密方式(22) 。
(22)
A. 邮件内容生成摘要,对摘要和内容用DES 算法加密
B. 邮件内容生成摘要,对摘要和内容用AES 算法加密
C. 邮件内容生成摘要,对内容用 IDEA 算法加密,对摘要和 IDEA 密钥用 A 算法加密
D. 对邮件内容用RSA 算法加密
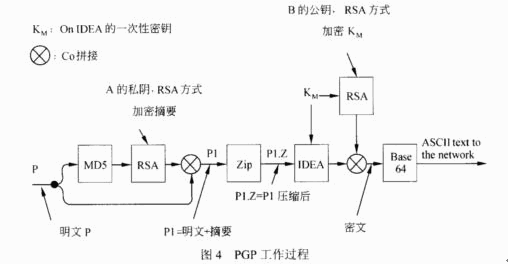
第5题:
消息摘要算法是一种常用的函数。MD5算法以一个任意长数据运动块作为输入,其输出为一个(23)比特的消息摘要。
A.128
B.160
C.256
D.512
第6题:
消息摘要算法MD5(message digest)是一种常用的Hash函数。MD5算法以一个任意长数据块作为输入,其输出为一个______比特的消息摘要。
A.128
B.160
C.256
D.512
第7题:
消息摘要算法MD5(Message Digest)是一种常用的(57)。MD5算法以一个任意长数据块作为输入,其输出为一个(58)比特的消息摘要。
A.索引算法
B.Hash函数
C.递归函数
D.倒排算法
第8题:
A、对称加密算法
B、非对称加密算法
C、数字摘要算法
D、Hash算法
第9题:
数字签名首先需要生成消息摘要,然后发送方用自己的私钥对报文摘要进行加密,接收方用发送方的公钥验证真伪。生成消息摘要的算法为( ) ,对摘要进行加密的算法为( )。
A.DESB.3DESC.MD5D.RSAA.DESB.3DESC.MD5D.RSA
第10题: