RRC连接建立后,UE通过RRC连接向RNC发送InitialDT,消息中携带UE发送到CN的NAS信息内容。()
主机A和B使用TCP通信。在B发送过的报文段中,有这样连续的两个:ACK=120 和ACK=100。这可能吗(前一个报文段确认的序号还大于后一个的)?试说明理由。
假定使用连续ARQ协议中,发送窗口大小事3,而序列范围[0.15],而传输媒体保证在接收方能够按序收到分组。在某时刻,接收方,下一个期望收到序号是5,试问:
(1)在发送方的发送窗口中可能有出现的序号组合有哪儿种?
接收方已经发送出去的、但在网络中(即还未到达发送方)的确认分组可能有哪些?说明这些确认分组是用来确认哪些序号的分组。
23、主机A向主机B连续发送了两个TCP报文段,其序号分别为70和100,试问:
(1)第一个报文段携带了多少个字节的数据?
(2)主机B收到第一个报文段后发回的确认中的确认号应当是多少?
(3)如果主机B收到第二个报文段后发回的确认中的确认号是180,试问A发送的第二个报文段中的数据有书少字节?
(4)如果A发送的第一个报文段丢失了,但第二个报文段到达了B,B在第二个报文段到达后向A,发送确认。试问这个确认号应为多少?
A、重传重要的数据段
B、放弃该连接
C、调整传送窗口尺寸
D、向另一个目标端口重传数据
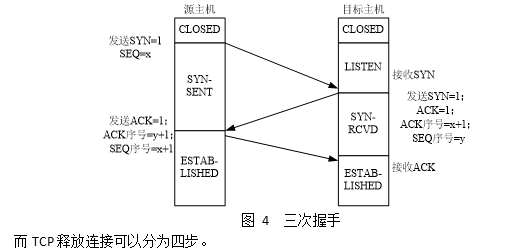
北京紫光华宇软件股份有限公司1月招聘面试题面试题面试官常问到的一些题目整理如下:问题 Q1:简述 三次握手、四次挥手的流程?可用的回答 : 三次握手: 初始状态:客户端A和服务器B均处于CLOSED状态,然后服务器B创建socket,调用监听接口使得服务器处于LISTEN状态,等待客户端连接。(后续内容用A,B简称代替) 1、A首先向B发起连接,这时TCP头部中的SYN标识位值为1,然后选定一个初始序号seq=x(一般是随机的), 消息发送后,A进入SYN_SENT状态,SYN=1的报文段不能携带数据,但要消耗一个序号。 2、B收到A的连接请求后,同意建立连接,向A发送确认数据,这时TCP头部中的SYN和ACK标识位值均为1,确认序号为ack=x+1, 然后选定自己的初始序号seq=y(一般是随机的),确认消息发送后, B进 入SYN_RCVD状态,与连接消息一样,这条消息也不能携带数据,同时消耗一个序号。 3、A收到B的确认消息后,需要给B回复确认数据,这时TCP头部中的ACK标识位值为1, 确认序号是ack=y+1,自己的序号在连接请求的序号上加1,也就是seq=x+1, 此时A进入ESTABLISHED状态,当B收到A的确认回复后,B也进入ESTABLISHED状态, 至此TCP成功建立连接,A和B之间就可以通过这个连接互相发送数据了。 四次挥手: 初始状态:客户端A和服务器B之间已经建立了TCP连接,并且数据发送完成,打算断开连接, 此时客户端A和服务器B是等价的,双方都可以发送断开请求,下面以客户端A主动发起断开请求为例。(后续内 容用A,B简称代替) 1、A首先向B发送断开连接消息,这时TCP头部中的FIN标识位值为1,序号是seq=m,m为A前面正常发送数据最后一个字节序号加1得到的, 消息发送后A进入FNI_WAIT_1状态,FIN=1的报文段不能携带数据,但要消耗一个序号。 2、B收到A的断开连接请求需要发出确认消息,这时TCP头部中的ACK标识位值为1,确认号为 ack=m+1, 而自己的序号为seq=n,n为B前面正常发送数据最后一个字节序号加1得到的, 然后B进入 CLOSE_WAIT状态,此时就关闭了A到B的连接, A无法再给B发数据,但是B仍然可以给A发数据,同时B端通知上方应用层,处理完成后被动关闭连接。 然后A收到B的确认信息后,就进入了 FIN_WAIT_2状态。 3、B端应用层处理完数据后,通知关闭连接, B向A发送关闭连接的消息,这时TCP头部中的FIN和ACK标识位值均为1, 确认号ack=m+1,自己的序号为seq=k,消息发送后B进入LACK_ACK状态。 4、A收到B的断开连接的消息后,需要发送确认消息, 这是这时TCP头部中的ACK标识位值为1,确认号ack=k+1,序号为m+1(因为A向B发送断开连接的消息时消耗了一个消息号), 然后A进入TIME_WAIT 状态,若等待时间经过2MSL后,没有收到B的重传请求, 则表明B收到了自己的确认,A进入CLOSED状态, B收到A的确认消息后则直接进入CLOSED状态。至此TCP成功断开连接。 问题 Q2:如何跨模块共享全局变量?可用的回答 :要在单个程序中跨模块共享全局变量,请创建一个特殊模块。在应用程序的所有模块中导入配置模块。该模块将作为跨模块的全局变量提供。问题 Q3:scrapy和scrapy-redis的区别?可用的回答 : scrapy是一个爬虫通用框架,但不支持分布式,scrapy-redis是为了更方便的实现scrapy分布式爬虫,而提供了一些以redis为基础的组件 为什么会选择redis数据库?因为redis支持主从同步,而且数据都是缓存在内存中,所以基于redis的分布式爬虫,对请求和数据的高频读取效率非常高 什么是主从同步?在Redis中,用户可以通过执行SLAVEOF命令或者设置slaveof选项, 让一个服务器去复制(replicate)另一个服务器,我们称呼被复制的服务器为主服务器(master),而对主服务器进行复制的服务器则被称为从服务器(slave), 当客户端向从服务器发送SLAVEOF命令,要求从服务器复制主服务器时,从服务器首先需要执行同步操作,也即是,将从服务器的数据库状态更新至主服务器当前所处的数据库状态 问题 Q4:介绍一下except的用法和作用?可用的回答 : tryexceptexceptelsefinally 执行try下的语句,如果引发异常,则执行过程会跳到except语句。 对每个except分支顺序尝试执行,如果引发的异常与except中的异常组匹配,执行相应的语句。 如果所有的except都不匹配,则异常会传递到下一个调用本代码的最高层try代码中。 try下的语句正常执行,则执行else块代码。如果发生异常,就不会执行 如果存在finally语句,最后总是会执行。 问题 Q5:如何跨模块共享全局变量?可用的回答 :要在单个程序中跨模块共享全局变量,请创建一个特殊模块。在应用程序的所有模块中导入配置模块。该模块将作为跨模块的全局变量提供。问题 Q6:写爬虫使用多进程好,还是用多线程好?可用的回答 : IO密集型代码(文件处理、网络爬虫等), 多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。 在实际的数据采集过程中,既考虑网速和响应的问题,也需要考虑自身机器的硬件情况,来设置多进程或多线程 问题 Q7:什么是反射?以及应用场景?可用的回答 : 通过字符串获取对象的方法称之为反射 python中可以通过如下方法实现: 1. getattr 获取属性 2. setattr 设置属性 3. hasattr 属性是否存在 4. delattr 删除属性 问题 Q8:描述数组、链表、队列、堆栈的区别?可用的回答 : 数组与链表是数据存储方式的概念,数组在连续的空间中存储数据,而链表可以在非连续的空间中存储数据;
● TCP 使用三次握手协议来建立连接,设甲乙双方发送报文的初始序号分别为 X和 Y,甲方发送 (69) 的报文给乙方,乙方接收报文后发送 (70) 的报文给甲方,然后甲方发送一个确认报文给乙方便建立了连接。
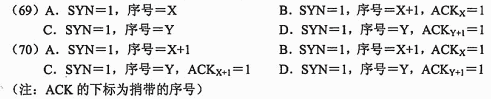
主机甲向主机乙发送一个TCP报文段,SYN字段为“1”,序列号字段的值为2000,若主机乙同意建立连接,则发送给主机甲的报文段可能为( ),若主机乙不同意建立连接,则( )字段置“1”
A. (SYN=1,ACK=1, seq=2001 ack=2001)B. (SYN=1 ,ACK=0,seq=2000 ack=2000)C (SYN=1,ÁCK=0, seq=2001 ack=2001)C. (SYN=0,ACK=1, seq=2000 ack=2000)A. URG B. RST C. PSH D. FIN
TCP使用三次握手协议来建立连接,设甲乙双方发送报文的初始序号分别为X和 Y,甲方发送(69)的报文给乙方,乙方接收报文后发送(70)的报文给甲方,然后甲方发送一个确认报文给乙方便建立了连接。
(注:ACK的下标为捎带的序号)
A.SYN=1,序号=X
B.SYN=1,序号=X+1,ACKX=1
C.SYN=1,序号=Y
D.SYN=1,序号=Y,ACKY+1=1