
散列表是一种重要的存储方式,在散列表里可快速进行检索。
(1)散列表的基本思想是什么?
(2)常用的散列函数有哪些,请举例说明(至少三个)。
(3)怎样用拉链法和开地址法处理碰撞?
第1题:
散列法存储中处理碰撞的方法主要有:【 】和开地址法。
第2题:
假定用散列函数H1=k mod 13计算散列地址,当发生冲突时,用散列函数 H2=k mod ll+l来计算下一个探测地址的地址增量。设散列表的地址空间为0~12,在地址2、3、8中,散列表相应的内容为80,85,34。下一个被插入的关键码是42,其插入的位置是【 】。
第3题:
● 下列有关数据存储结构的叙述中,正确的是“ (44) ”和“ (45) ”。
(44)
A. 顺序存储方式只能用于存储线性结构
B. 顺序存储方式的优点是存储密度,插入、删除运算效率高
C. 链表的每个结点中都恰好包含一个指针
D. 队列的存储方式既可以是顺序方式,也可以是链接方式
(45)
A. 散列表的结点中只包含数据元素自身的信息,不包含任何指针
B. 负载因子(装填因子)是散列法一个重要参数,它反映散列表装满程度
C. 散列法存储的基本思想是把关键字的值作为数据的存储地址
D. 在散列法中,不同的关键字值对应到不同的存储地址称作发生了冲突
第4题:
散列法存储中处理碰撞的方法主要有两类:拉链法和 【】
第5题:
散列法存储中处理碰撞的方法主要有两类,开地址法和【】。
第6题:
设有两个散列函数H1(k)=kmod 13和H2(k)=kmod 11+1,散列表为T[0…12],用二次散列法解决冲突。函数H1用来计算散列地址,当发生冲突时,H2作为计算下一个探测地址的地址增量。假定某一时刻散列表的状态为:

下一个被插入的关键码为42,其插入位置应是( )。
A.0
B.1
C.3
D.4
第7题:
已知一个线性表(38,25,74,63,52,48),假定采用散列函数h(key)=key%7计算散列地址,并散列存储在散列表A[0…6]中,若采用线性探测法解决冲突,则在该散列表上进行等概率成功查找的平均查找长度为(63)。
A.1.4
B.1.6
C.2.0
D.2.2

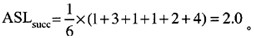
第8题:
以下说法错误的是()。
A.散列法存储的思想是由关键字值决定数据的存储地址
B.散列表的结点中只包含数据元素自身的信息,不包含指针
C.负载因子是散列表的一个重要参数,它反映了散列表的饱满程度
D.散列表的查找效率主要取决于散列表构造时选取的散列函数和处理冲突的方法
第9题:
以下说法错误的是(42)。
A.装填因子是散列法的一个重要参数,它反映了散列表的装填程度
B.散列表的查找效率主要取决于散列表造表时选取的散列函数和处理冲突的方法
C.散列表的结点中只包含数据元素自身的信息,不包含任何指针
D.散列法存储的基本思想是由关键码值决定数据的存储地址
第10题:
下列问题是基于下列描述:散列表的地址区间为0~17,散列函数为H(K)=Kmod 17采用线性探测法处理冲突,并将关键字序列26、25、72、38、8、18、59依次存储到散列表中。
元素59存放在散列表中的地址是( )。
A.8
B.9
C.10
D.11