
请根据《风景名胜区管理暂行条例》的规定,回答以下问题:
(1)我国风景名胜区具体划分为哪几个等级?(2分)
(2)我国风景名胜区的划分依据是什么?(2分)
答案:(1)我国风景名胜区划分为三个等级:市县级风景名胜区:省级风景名胜区:国家重点风景名胜区。
(2) 一是风景名胜区内景物的观赏、文化、科学价值;二是环境质量、规模大小、游览条件。
此题为判断题(对,错)。
A.spiders文件夹
B.item.py
C.pipeline.py
D.settings.py
模块独立性是由内聚和耦合两个定性指标来度量的。回答下列问题:
1.什么是内聚?什么是耦合?
2.内聚分为哪几类?耦合分为哪几类?
3.什么是时间内聚?什么是公共耦合?
上海依图网络科技有限公司8月招聘面试题面试题面试官常问到的一些题目整理如下:问题 Q1:说一说redis-scrapy中redis的作用?可用的回答 : 它是将scrapy框架中Scheduler替换为redis数据库,实现队列管理共享。 优点: 可以充分利用多台机器的带宽; 可以充分利用多台机器的IP地址。 问题 Q2:如何在Python中复制对象?可用的回答 :要在Python中复制对象,可以尝试copy.copy() 或 copy.deepcopy() 来处理一般情况。copy.copy()浅拷贝,复制引用;copy.deepcopy()深拷贝,完全独立的对象问题 Q3::-1表示什么?可用的回答 ::-1用于反转数组或序列的顺序。问题 Q4: scrapy分为几个组成部分?分别有什么作用?可用的回答 : 分为5个部分; 1. Spiders(爬虫类) 2. Scrapy Engine(引擎) 3. Scheduler(调度器) 4. Downloader(下载器) 5. Item Pipeline(处理管道) 具体来说: Spiders:开发者自定义的一个类,用来解析网页并抓取指定url返回的内容。 Scrapy Engine:控制整个系统的数据处理流程,并进行事务处理的触发。 Scheduler:接收Engine发出的requests,并将这些requests放入到处理列队中,以便之后engine需要时再提供。 Download:抓取网页信息提供给engine,进而转发至Spiders。 Item Pipeline:负责处理Spiders类提取之后的数据。 比如清理HTML数据、验证爬取的数据(检查item包含某些字段)、查重(并丢弃)、将爬取结果保存到数据库中 问题 Q5:如果让你来防范网站爬虫,你应该怎么来提高爬取的难度?可用的回答 : 1. 判断headers的User-Agent; 2. 检测同一个IP的访问频率; 3. 数据通过Ajax获取; 4. 爬取行为是对页面的源文件爬取,如果要爬取静态网页的html代码,可以使用jquery去模仿写html。 问题 Q6:Post和get区别?可用的回答 : 1. 请求数据 GET请求,请求的数据会附加在URL之后,以?分割URL和传输数据,多个参数用&连接。URL的编码格式 采用的是ASCII编码,而不是uniclde,即是说所有的非ASCII字符都要编码之后再传输。 POST请求:POST请求会把请求的数据放置在HTTP请求包的包体中。上面的item=bandsaw就是实际的传输数据。 因此,GET请求的数据会暴露在地址栏中,而POST请求则不会。 2、传输数据的大小 在HTTP规范中,没有对URL的长度和传输的数据大小进行限制。但是在实际开发过程中,对于GET,特定的浏览器和服务器对URL的长度有限制。 因此,在使用GET请求时,传输数据会受到URL长度的限制。 对于POST,由于不是URL传值,理论上是不会受限制的,但是实际上各个服务器会规定对POST提交数据大小进行限制,Apache、IIS都有各自的配置。 3、安全性 POST的安全性比GET的高。这里的安全是指真正的安全,而不同于上面GET提到的安全方法中的安全, 上面提到的安全仅仅是不修改服务器的数据。比如,在进行登录操作,通过GET请求,用户名和密码都会暴露再URL上, 因为登录页面有可能被浏览器缓存以及其他人查看浏览器的历史记录的原因,此时的用户名和密码就很容易被他人拿到了。 除此之外,GET请求提交的数据还可能会造成Cross-site requestfrogery攻击。 问题 Q7:什么是_init_?可用的回答 :_init_是Python中的方法或者结构。在创建类的新对象/实例时,将自动调用此方法来分配内存。所有类都有_init_方法。问题 Q8:写爬虫使用多进程好,还是用多线程好?可用的回答 : IO密集型代码(文件处理、网络爬虫等), 多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。 在实际的数据采集过程中,既考虑网速和响应的问题,也需要考虑自身机器的硬件情况,来设置多进程或多线程 问题 Q9:Python里面match()和search()的区别?可用的回答 :re模块中match(pattern,string,flags),检查string的开头是否与pattern匹配。re模块中research(pattern,string,flags),在string搜索pattern的第一个匹配值。问题 Q10:常见的HTTP方法有哪些?可用的回答 : GET:请求指定的页面信息,返回实体主体; HEAD:类似于get请求,只不过返回的响应中没有具体的内容,用于捕获报头; POST:向指定资源提交数据进行处理请求(比如表单提交或者上传文件),。数据被包含在请求体中。 PUT:从客户端向服务端传送数据取代指定的文档的内容; DELETE:请求删除指定的页面; CONNNECT:HTTP1.1协议中预留给能够将连接方式改为管道方式的代理服务器; OPTIONS:允许客户端查看服务器的性能; TRACE:回显服务器的请求,主要用于测试或者诊断。 算法题面试官常问到的一些算法题目整理如下(大概率会机考):算题题 A1:3D图形的表面区域题目描述如下:Contest 1:On a N * N grid, we place some 1 * 1 * 1 cubes.Each value v = gridij represents a tower of v cubes placed on top of grid cell (i, j).Return the total surface area of the resulting shapes. Example 1:Input: 2Output: 10Example 2:Input: 1,2,3,4Output: 34Example 3:Input: 1,0,0,2Output: 16Example 4:Input: 1,1,1,1,0,1,1,1,1Output: 32Example 5:Input: 2,2,
结构化方法将软件生存期分为计划、开发、运行三个大的阶段,每个阶段又分为若干个阶段,各阶段的工作按顺序开展,回答下列问题:
1.计划阶段的主要任务是什么,它分为哪几个阶段?
2.开发阶段的主要任务是什么,它分为哪几个阶段?
3.运行阶段的主要任务是什么,它分为哪几个阶段?
阅读以下算法说明,根据要求回答问题1~问题3。
[说明]
快速排序是一种典型的分治算法。采用快速排序对数组A[p..r]排序的3个步骤如下。
1.分解:选择一个枢轴(pivot)元素划分数组。将数组A[p..r]划分为两个子数组(可能为空)A[p..q-1]和A[q+1..r],使得A[q]大于等于A[p..q-1]中的每个元素,小于A[q+1..r]中的每个元素。q的值在划分过程中计算。
2.递归求解:通过递归的调用快速排序,对子数组A[p..q-1]和A[q+1..r]分别排序。
3.合并:快速排序在原地排序,故无需合并操作。
下面是快速排序的伪代码,请将空缺处(1)~(3)的内容填写完整。伪代码中的主要变量说明如下。
A:待排序数组
p,r:数组元素下标,从p到r
q:划分的位置
x:枢轴元素
i:整型变量,用于描述数组下标。下标小于或等于i的元素的值,小于或等于枢轴元素的值
j:循环控制变量,表示数组元素下标

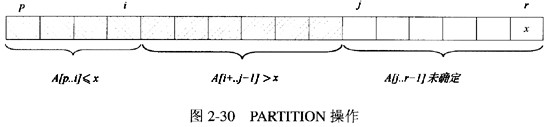 在[问题1]所给出的伪代码中当for循环结束后A[p..i]中的值应小于等于枢轴元素值x而A[i+1..r-1]中的值应大于枢轴元素值x。此时A[i+1]是第一个比A[r]大的元素因此A[r]与A[i+1]进行交换得到划分后的两个子数组。PARTITION操作返回枢轴元素的位置因此返回值为i+l。
在[问题1]所给出的伪代码中,当for循环结束后,A[p..i]中的值应小于等于枢轴元素值x,而A[i+1..r-1]中的值应大于枢轴元素值x。此时A[i+1]是第一个比A[r]大的元素,因此A[r]与A[i+1]进行交换,得到划分后的两个子数组。PARTITION操作返回枢轴元素的位置,因此返回值为i+l。
在[问题1]所给出的伪代码中当for循环结束后A[p..i]中的值应小于等于枢轴元素值x而A[i+1..r-1]中的值应大于枢轴元素值x。此时A[i+1]是第一个比A[r]大的元素因此A[r]与A[i+1]进行交换得到划分后的两个子数组。PARTITION操作返回枢轴元素的位置因此返回值为i+l。
在[问题1]所给出的伪代码中,当for循环结束后,A[p..i]中的值应小于等于枢轴元素值x,而A[i+1..r-1]中的值应大于枢轴元素值x。此时A[i+1]是第一个比A[r]大的元素,因此A[r]与A[i+1]进行交换,得到划分后的两个子数组。PARTITION操作返回枢轴元素的位置,因此返回值为i+l。
What’s the difference between deep copy and shallow copy?
(深拷贝与浅拷贝有什么区别)
一、根据“给定材料1-5”,回答下列问题。 1.市政公用事业建设有哪些主要内容,并谈谈市政公用事业的重要性。(10分) 要求:准确、简明。不超过150字。
2.“给定资料1”里说“连健康都算不上”指的是什么问题?问题存在的原因是什么?(10分) 要求:全面、准确,有条理,不超过100字。
1、市政公用事业建设具有先导性、基础性、公益性,包括:城市供水、集中供热、垃圾处理、市政交通、园林绿化、污水处理、管道燃气八个方面。它是城市经济发展的载体,建设并管理好城市市政公用设施,对经济发展具有先导、基础的作用;对促进城市经济稳定健康发展,对城市功能、质量的提高和城市现代化建设具有特别重要的意义。
2、 给定资料一里说“连健康都算不上”指的是:城市市政公用事业建设发展滞后,不能满足城市化的需要,之所以存在这种现象,是由于地方政府对城市公用事业的重视程度不高,在这方面资金投入不足,比例很小,规模不大。
四)请仔细阅读给定资料,回答下面两个问题。(25分)
1.南方某市网上泄密包括哪些泄密事件,原因和问题是什么?(15分)
2.阐述信息公开与保密的关系。(10分)
(1)该地领导在涉密会议上的讲话泄密事件。原因是定密程序不完善,保密审核人员失职。该讲话内容属于机密级国家秘密,泄密可能危害公共利益和安全。
(2)中央C部委文件泄密事件。原因是政府急于公布信息以求经济发展,保密意识淡薄;政府专业人员不足,存在代履职行为。该文件涉及许多企业利益,泄密有可能导致第三方利益受损。代履职人员由于相关保密知识不足及利益驱动易引发泄密事件。
2.信息公开与保密是对立统一的,二者统一于国家利益。信息公开是保障人民群众的知情权和监督权、建设服务型政府的题中之义,保密是维护国家安全和利益的必然要求。信息公开并不是无原则地公开,泄密会危害公共利益及国家安全,反而不利于服务型政府的建设。在实际工作中,我们要严格保密审核,及时公开合法信息,做到信息公开与保密的和谐统一。