
快速排序算法在排序过程中,在待排序数组中确定一个元素为基准元素,根据基准元素把待排序数组划分成两个部分,前面一部分元素值小于等于基准元素,而后面一部分元素值大于基准元素。然后再分别对前后两个部分进一步进行划分。根据上述描述,快速排序算法采用了()算法设计策略。
第1题:
以下关于快速排序算法的描述中,错误的是( )。在快速排序过程中,需要设立基准元素并划分序列来进行排序。若序列由元素{12,25,30,45,52,67,85}构成,则初始排列为( )时,排序效率最高(令序列的第一个元素为基准元素)。
A.快速排序算法是不稳定的排序算法
B.快速排序算法在最坏情况下的时间复杂度为0(nlgn)
C.快速排序算法是一种分治算法
D.当输入数据基本有序时,快速排序算法具有最坏情况下的时间复杂度
第2题:
阅读以下算法说明,根据要求回答问题1~问题3。
[说明]
快速排序是一种典型的分治算法。采用快速排序对数组A[p..r]排序的3个步骤如下。
1.分解:选择一个枢轴(pivot)元素划分数组。将数组A[p..r]划分为两个子数组(可能为空)A[p..q-1]和A[q+1..r],使得A[q]大于等于A[p..q-1]中的每个元素,小于A[q+1..r]中的每个元素。q的值在划分过程中计算。
2.递归求解:通过递归的调用快速排序,对子数组A[p..q-1]和A[q+1..r]分别排序。
3.合并:快速排序在原地排序,故无需合并操作。
下面是快速排序的伪代码,请将空缺处(1)~(3)的内容填写完整。伪代码中的主要变量说明如下。
A:待排序数组
p,r:数组元素下标,从p到r
q:划分的位置
x:枢轴元素
i:整型变量,用于描述数组下标。下标小于或等于i的元素的值,小于或等于枢轴元素的值
j:循环控制变量,表示数组元素下标

 在[问题1]所给出的伪代码中当for循环结束后A[p..i]中的值应小于等于枢轴元素值x而A[i+1..r-1]中的值应大于枢轴元素值x。此时A[i+1]是第一个比A[r]大的元素因此A[r]与A[i+1]进行交换得到划分后的两个子数组。PARTITION操作返回枢轴元素的位置因此返回值为i+l。
在[问题1]所给出的伪代码中,当for循环结束后,A[p..i]中的值应小于等于枢轴元素值x,而A[i+1..r-1]中的值应大于枢轴元素值x。此时A[i+1]是第一个比A[r]大的元素,因此A[r]与A[i+1]进行交换,得到划分后的两个子数组。PARTITION操作返回枢轴元素的位置,因此返回值为i+l。
在[问题1]所给出的伪代码中当for循环结束后A[p..i]中的值应小于等于枢轴元素值x而A[i+1..r-1]中的值应大于枢轴元素值x。此时A[i+1]是第一个比A[r]大的元素因此A[r]与A[i+1]进行交换得到划分后的两个子数组。PARTITION操作返回枢轴元素的位置因此返回值为i+l。
在[问题1]所给出的伪代码中,当for循环结束后,A[p..i]中的值应小于等于枢轴元素值x,而A[i+1..r-1]中的值应大于枢轴元素值x。此时A[i+1]是第一个比A[r]大的元素,因此A[r]与A[i+1]进行交换,得到划分后的两个子数组。PARTITION操作返回枢轴元素的位置,因此返回值为i+l。
第3题:
A.分治
B.动态规划
C.贪心
D.回溯
第4题:
●试题二
阅读下列说明、流程图和算法,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
下面的流程图(如图3所示)用N-S盒图形式描述了数组A中的元素被划分的过程。其划分方法是:以数组中的第一个元素作为基准数,将小于基准数的元素向低下标端移动,而大于基准数的元素向高下标端移动。当划分结束时,基准数定位于A[i],并且数组中下标小于i的元素的值均小于基准数,下标大于i的元素的值均大于基准数。设数组A的下界为low,上界为high,数组中的元素互不相同。例如,对数组(4,2,8,3,6),以4为基准数的划分过程如下:
【流程图】
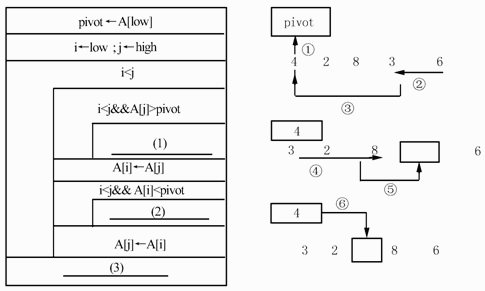
图3流程图
【算法说明】
将上述划分的思想进一步用于被划分出的数组的两部分,就可以对整个数组实现递增排序。设函数int p(int A[],int low,int high)实现了上述流程图的划分过程并返回基准数在数组A中的下标。递归函数void sort(int A[],int L,int H)的功能是实现数组A中元素的递增排序。
【算法】
void sort (int A[], int 1,int H){
if ( L<H){
k=p(A,L,R);//p()返回基准数在数组A中的下标
sort( (4) );//小于基准数的元素排序
sort( (5) );//大于基准数的元素排序
}
}
第5题:
阅读下列说明、流程图和算法,将应填入(n)处的字句写在对应栏内。
【流程图说明】
下图所示的流程图5.3用N-S盒图形式描述了数组Array中的元素被划分的过程。其划分方法;以数组中的第一个元素作为基准数,将小于基准数的元素向低下标端移动,而大于基准数的元素向高下标端移动。当划分结束时,基准数定位于Array[i],并且数组中下标小于i的元素的值均小于基准数,下标大于i的元素的值均大于基准数。设数组A的下界为low,上界为high,数组中的元素互不相同。

【算法说明】
将上述划分的思想进一步用于被划分出的数组的两部分,就可以对整个数组实现递增排序。设函数int p(int Array[],int low,int high)实现了上述流程图的划分过程并返回基准数在数组Ar ray中的下标。递归函数void sort(int Array[],int L,int H)的功能是实现数组Array中元素的递增排序。
【算法】
void sort(int Array[],int L,int H){
if (L<H) {
k=p(Array,L,H);/*p()返回基准数在数组Array中的下标*/
sort((4));/*小于基准数的元素排序*/
sort((5));/*大于基准数的元素排序*/
}
}
第6题:
阅读下列说明、流程图和算法,将应填(n)处的字句写在对应栏内。
[说明]
下面的流程图(如图3所示)用N - S盒图形式描述了数组A中的元素被划分的过程。其划分方法是:以数组中的第一个元素作为基准数,将小于基准数的元素向低下标端移动,而大于基准数的元素向高下标端移动。当划分结束时,基准数定位于A[i],并且数组中下标小于i的元素的值均小于基准数,下标大于i的元素的值均大于基准数。设数组A的下界为 low,上界为high,数组中的元素互不相同。例如,对数组(4,2,8,3,6),以4为基准数的划分过程如下:

[流程图]
[算法说明]
将上述划分的思想进一步用于被划分出的数组的两部分,就可以对整个数组实现递增排序。设函数int p(int A[],int low,int hieh)实现了上述流程图的划分过程并返回基准数在数组A中的下标。递归函数void sort(int A[],int L,int H)的功能是实现数组A中元素的递增排序。
[算法]
void sort(int A[],int L,int H) {
if (L<H) {
k=p(A,L,R); //p()返回基准数在数组A中的下标
sort((4)); //小于基准敷的元素排序
sort((5)); //大于基准数的元素排序
}
}
第7题:
A、快速排序
B、冒泡排序
C、简单选择排序D、归并排序
第8题:
● 以下关于快速排序算法的描述中,错误的是 (64) 。在快速排序过程中,需要设立基准元素并划分序列来进行排序。若序列由元素{12,25,30,45,52,67,85}构成,则初始排列为 (65) 时,排序效率最高(令序列的第一个元素为基准元素)。
(64)A. 快速排序算法是不稳定的排序算法
B. 快速排序算法在最坏情况下的时间复杂度为O(n1gn)
C. 快速排序算法是一种分治算法
D. 当输入数据基本有序时,快速排序算法具有最坏情况下的时间复杂度
(65)A. 45,12,30,25,67,52,85
B. 85,67,52,45,30,25,12
C. 12,25,30,45,52,67,85
D. 45,12,25,30,85,67,52
第9题:
快速排序算法在排序过程中,在待排序数组中确定一个元素为基准元素,根据基准元素把待排序数组划分成两个部分,前面一部分元素值小于等于基准元素,而后面一部分元素值大于基准元素。然后再分别对前后两个部分进一步进行划分。根据上述描述,快速排序算法采用了 (61) 算法设计策略。已知确定基准元素操作的时间复杂度为 ,则快速排序算法的最好和最坏情况下的时间复杂度为 (62) 。
,则快速排序算法的最好和最坏情况下的时间复杂度为 (62) 。
A.分治
B.动态规划
C.贪心
D.回溯
第10题:
● 如果待排序序列中两个元素具有相同的值,在排序前后它们的相互位置发生颠倒,则称该排序算法是不稳定的。 (41) 是稳定的排序方法,因为这种方法在比较相邻元素时,值相同的元素并不进行交换。
(41)
A. 冒泡排序
B. 希尔排序
C. 快速排序
D. 简单选择排序
