
●试题一
阅读下列说明和流程图,将应填入(n)的语句写在答题纸的对应栏内。
【流程图说明】
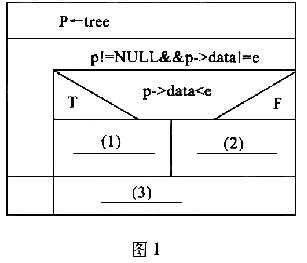
下面的流程(如图1所示)用N-S盒图形式描述了在一棵二叉树排序中查找元素的过程,节点有3个成员:data,left和right。其查找的方法是:首先与树的根节点的元素值进行比较:若相等则找到,返回此结点的地址;若要查找的元素小于根节点的元素值,则指针指向此结点的左子树,继续查找;若要查找的元素大于根节点的元素值,则指针指向此结点的右子树,继续查找。直到指针为空,表示此树中不存在所要查找的元素。
【算法说明】
【流程图】
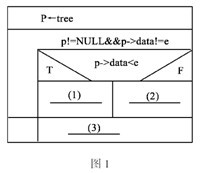
将上题的排序二叉树中查找元素的过程用递归的方法实现。其中NODE是自定义类型:
typedef struct node{
int data;
struct node*left;
struct node*right;
}NODE;
【算法】
NODE*SearchSortTree(NODE*tree,int e)
{
if(tree!=NULL)
{
if(tree->data<e)
(4) ;∥小于查找左子树
else if(tree->data<e)
(5) ;∥大于查找左子树
else return tree;
}
return tree;
}
第1题:
阅读以下说明和流程图,回答问题1~2,将解答填入对应的解答栏内。
[说明]
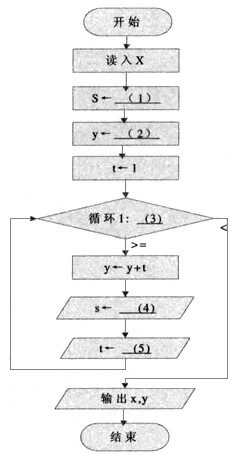
下面的流程图描述了计算自然数1到N(N≥1)之和的过程。
[流程图]
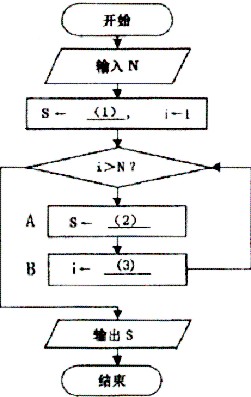
[问题1] 将流程图中的(1)~(3)处补充完整。
[问题2] 为使流程图能计算并输出1*3+2*4+…+N*(N+2)的值,A框内应填写(4);为使流程图能计算并输出不大于N的全体奇数之和,B框内应填写(5)。
第2题:
阅读下列说明和流程图,将应填入(n)的字句写在对应栏内。
【说明】
下列流程图(如图4所示)用泰勒(Taylor)展开式
sinx=x-x3/3!+x5/5!-x7/7!+…+(-1)n×x2n+1/(2n+1)!+…
【流程图】
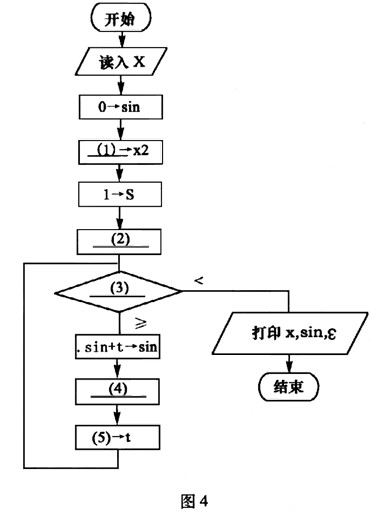
计算并打印sinx的近似值。其中用ε(>0)表示误差要求。
第3题:
阅读下列说明和流程图,将应填入(n)处的语句写在对应栏内。
【说明】
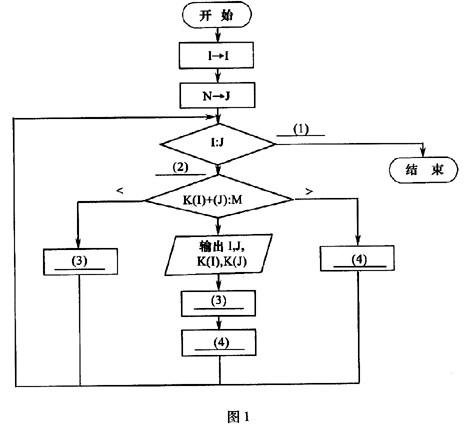
下列流程图用于从数组K中找出一切满足:K(I)+K(J)=M的元素对(K(I),K(J))(1≤I≤J≤N)。假定数组K中的N个不同的整数已按从小到大的顺序排列,M是给定的常数。
【流程图】
此流程图1中,比较“K(I)+K(J):M”最少执行次数约为(5)。
第4题:
阅读下列说明和流程图,将应填入(n)处的语句写在对应栏内。
【说明】
有数组A(4,4),把1到16个整数分别按顺序放入A(1,1),…,A(1,4),A(2,1),…,A(2,4),A(3,1),…,A(3,4),A(4,1),…,A(4,4)中,下面的流程图用来获取数据并求出两条对角线元素之积。
【流程图】

第5题:
阅读下列说明和流程图,将应填入(n)处的语句写在对应栏内。
【说明】
下列流程图用泰勒(Taylor)展开式y=ex=1+x+x2/2!+x3/3!+…+xn/n!+…计算并打印ex的近似值,其中用ε(>0)表示误差要求。
【流程图】
第6题:
阅读以下说明和流程图,将应填入(n)处的字句写在对应栏内。
[说明]
设学生某次考试的成绩按学号顺序逐行存放于某文件中,文件以单行句点“.”为结束符。下面的流程图读取该文件,统计出全部成绩中的最高分max和最低分min。

第7题:
阅读以下说明和流程图,填补流程图中的空缺(1)一(5),将解答填入答题纸的对应栏内。
【说明】
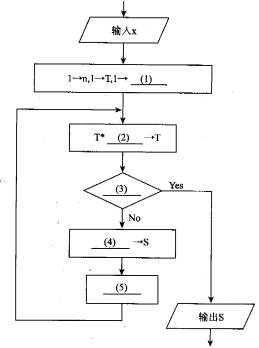
下面的流程图采用公式ex=1+x+x2/2 1+x3/3 1+x4/4 1+…+xn/n!+???计算ex的近似值。设x位于区间(0,1),该流程图的算法要点是逐步累积计算每项xx/n!的值(作为T),再逐步累加T值得到所需的结果s。当T值小于10-5时,结束计算。
【流程图】
第8题:
阅读以下说明和流程图,将应填入(n)处的字句写在对应栏内。
【说明】
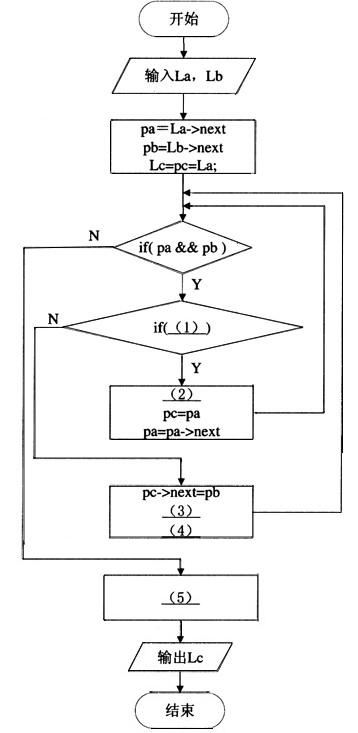
已知头指针分别为La和lb的有序单链表,其数据元素都是按值非递减排列。现要归并La和Lb得到单链表Lc,使得Lc中的元素按值非递减排列。程序流程图如下所示:
第9题:
阅读以下说明和流程图,填补流程图中的空缺(1)~(9),将解答填入对应栏内。
【说明】
假设数组A中的各元素A(1),A(2),…,A(M)已经按从小到大排序(M≥1);数组B中的各元素B(1),B(2),…,B(N)也已经按从小到大排序(N≥1)。执行下面的流程图后,可以将数组A与数组B中所有的元素全都存入数组C中,且按从小到大排序 (注意:序列中相同的数全部保留并不计排列顺序)。例如,设数组A中有元素:2,5, 6,7,9;数组B中有元素2,3,4,7:则数组C中将有元素:2,2,3,4,5,6,7, 7, 9。
【流程图】

第10题:
阅读下列说明和流程图,将应填入(n)的语句写在对应栏内。
【流程图说明】
下面的流程(如图1所示)用N-S盒图形式描述了在一棵二叉树排序中查找元素的过程,节点有3个成员:data, left和right。其查找的方法是:首先与树的根节点的元素值进行比较:若相等则找到,返回此结点的地址;若要查找的元素小于根节点的元素值,则指针指向此结点的左子树,继续查找;若要查找的元素大于根节点的元素值,则指针指向此结点的右子树,继续查找。直到指针为空,表示此树中不存在所要查找的元素。
【算法说明】
【流程图】
将上题的排序二叉树中查找元素的过程用递归的方法实现。其中NODE是自定义类型:
typedef struct node {
int data;
struct node * left;
struct node * right;
}NODE;
【算法】
NODE * SearchSortTree(NODE * tree, int e)
{
if(tree!=NULL)
{
if(tree->data<e)
(4); //小于查找左子树
else if(tree->data<e)
(5); //大于查找左子树
else return tree;
}
return tree;
}