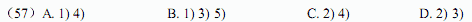路由选择协议的一个要求就是必须能够快速收敛,所谓“路由收敛”是指( )。
A)路由器把分组发送到预定的目标
B)路由器处理分组的速度足够快
C)文件系统管理的数据量比较少,而数据库系统可以管理巨大的数据量
D)网络设备的路由表和网络拓扑结构保持一致
A.数据量大的表分放在不同磁盘上
B.将I/O访问分布在尽可能多的磁盘上
C.将访问量最大的几个不同的表,分放在不同磁盘上
D.数据表和索引放在一起存储
下面关于基本表选择合适的文件结构的原则错误的是______。
A.如果数据库中的一个基本表中的数据量很少,操作很频繁,该基本表可以采用堆文件组织方式
B.顺序文件支持基于查找码的顺序访问,也支持快速的二分查找
C.如果用户查询是基于散列阈值的等值匹配,散列文件比较合适
D.如果某些重要而频繁的用户查询经常需要进行多表连接操作的,可以考虑将表组织成为非聚集文件
以下关于聚集文件及其操作叙述错误的是______。
A) 聚集文件是一种具有多种记录类型的文件
B) 聚集文件存储了来自多个关系表的数据
C) 聚集文件中每个关系表对应文件中的记录类型是相同的
D) 聚集文件将不同关系表中有关联关系的记录存储在同一磁盘块内,从而减少数据库多表查询操作时的磁盘块访问次数,提高系统I/O速度和查找处理速度
A.
B.
C.
D.
如果数据库中的一个基本表中的数据量很少,且插入、删除、更新等操作频繁,该基本表最佳采用的文件结构是______。
广州市品高软件股份有限公司 11月招聘面试题 面试题 面试官常问到的一些题目整理如下: 问题 Q1:数据库的优化? 可用的回答 : 1. 优化索引、SQL 语句、分析慢查询; 2. 设计表的时候严格根据数据库的设计范式来设计数据库; 3. 使用缓存,把经常访问到的数据而且不需要经常变化的数据放在缓存中,能节约磁盘IO; 4. 优化硬件;采用SSD,使用磁盘队列技术(RAID0,RAID1,RDID5)等; 5. 采用MySQL 内部自带的表分区技术,把数据分层不同的文件,能够提高磁盘的读取效率; 6. 垂直分表;把一些不经常读的数据放在一张表里,节约磁盘I/O; 7. 主从分离读写;采用主从复制把数据库的读操作和写入操作分离开来; 8. 分库分表分机器(数据量特别大),主要的的原理就是数据路由; 9. 选择合适的表引擎,参数上的优化; 10. 进行架构级别的缓存,静态化和分布式; 11. 不采用全文索引; 12. 采用更快的存储方式,例如 NoSQL存储经常访问的数据 问题 Q2:如何在Python中实现多线程? 可用的回答 :Python有一个多线程库,但是用多线程来加速代码的效果并不是那么的好, Python有一个名为Global Interpreter Lock(GIL)的结构。 GIL确保每次只能执行一个“线程”。一个线程获取GIL执行相关操作,然后将GIL传递到下一个线程。 虽然看起来程序被多线程并行执行,但它们实际上只是轮流使用相同的CPU核心。 有这些GIL传递都增加了执行的开销。这意味着多线程并不能让程序运行的更快 问题 Q3:描述一下scrapy框架的运行机制? 可用的回答 : 从start_urls里面获取第一批url发送请求,请求由请求引擎给调度器入请求对列,获取完毕后, 调度器将请求对列交给下载器去获取请求对应的响应资源,并将响应交给自己编写的解析方法做提取处理,如 果提取出需要的数据,则交给管道处理,如果提取出url,则继续执行之前的步骤,直到多列里没有请求,程序结束。 问题 Q4:IO多路复用的作用? 可用的回答 : 基本概念 IO多路复用是指内核一旦发现进程指定的一个或者多个IO条件准备读取,它就通知该进程。 IO多路复用适用如下场合: (1)当客户处理多个描述字时(一般是交互式输入和网络套接口),必须使用I/O复用。 (2)当一个客户同时处理多个套接口时,而这种情况是可能的,但很少出现。 (3)如果一个TCP服务器既要处理监听套接口,又要处理已连接套接口,一般也要用到I/O复用。 (4)如果一个服务器即要处理TCP,又要处理UDP,一般要使用I/O复用。 (5)如果一个服务器要处理多个服务或多个协议,一般要使用I/O复用。 与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小, 系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。 问题 Q5:什么是_init_? 可用的回答 :_init_是Python中的方法或者结构。在创建类的新对象/实例时,将自动调用此方法来分配内存。所有类都有_init_方法。 问题 Q6:有哪些工具可以帮助查找错误或执行静态分析? 可用的回答 : PyChecker是一个静态分析工具,可以检测Python源代码中的错误,并警告错误的风格和复杂性。 Pylint是另一种验证模块是否符合编码标准的工具。 auto-pep8工具也可以进行静态代码检查 问题 Q7: Tornado 的核心是什么? 可用的回答 : Tornado 的核心是 ioloop 和 iostream 这两个模块, 前者提供了一个高效的 I/O 事件循环,后者则封装了 一个无阻塞的 socket 。 通过向 ioloop 中添加网络 I/O 事件,利用无阻塞的 socket, 再搭配相应的回调函数,便可达到梦寐以求的高效异步执行。 问题 Q8:什么是粘包? socket 中造成粘包的原因是什么? 哪些情况会发生粘包现象? 可用的回答 : 粘包:在接收数据时,一次性多接收了其它请求发送来的数据(即多包接收)。如: 对方第一次发送hello,第二次发送world,在接收时,应该收两次, 一次是hello,一次是world,但事实上是一次收到helloworld,一次收到空,这种现象叫粘包。 原因: 粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。 什么情况会发生: 1、发送端需要等缓冲区满才发送出去,造成粘包 发送数据时间间隔很短,数据很小,会合到一起,产生粘包 2、接收方不及时接收缓冲区的包,造成多个包接收 客户端发送了一段数据,服务端只收了一小部分, 服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包 解决方案: 一个思路是发送之前,先打个招呼,告诉对方自己要发送的字节长度, 这样对方可以根据长度判断什么时候终止接受 注意: 只有TCP有粘包现象,UDP永远不会粘包! 问题 Q9:什么是arp协议? 可用的回答 : ARP(Address Resolution Protocol)即地址解析协议, 用于实现从 IP 地址到 MAC 地址的映射,即询问目标IP对应的MAC地址。 问题 Q10:什么是Python pass? 可用的回答 :pass意味着,无操作的Python语句,或者换句话说,它是复合语句中的占位符,其中应该留有空白,并且不必在那里写入任何内容。 算法题 面试官常问到的一些算法题目整理如下(大概率会机考): 算题题 A1:排序矩阵中第k小个元素 题目描述如下: Given a n x n matrix where each of the rows and columns are sorted in ascending order, find the kth smallest element in the matrix. Note that it is the kth smallest element in the sorted order, not the kth distinct element. Example: matrix = 1, 5, 9, 10, 11, 13, 12, 13, 15 , k = 8, return 13. Note: You may assume k is always valid, 1 k n2. 找到第k小个数。 测试用例: 思路是用了堆: 、Python 有内置的堆模块,需要进行研究自写。 2018/08/02待跟进。 堆: 堆是一个完全二叉树,完全二叉树是除了最底层,其他层都是铺满的。 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 堆又分为最大堆与最小堆,最小堆是根节点是整个堆中最小的,最大堆则是最大的。 堆的操作分为:插入,取顶。 大部分情况下插入时的数据都是无序的,所以要保证最大堆与最小堆需要的操作肯定要有上浮与下沉。 上浮: 最小堆中: 如果父节点比自己大则自己上浮。 如果子节点比自己小则自己下沉。 也就是做数据交换,一直上浮或下沉到符合条
优化数据库数据的存储结构和存取方法有利于提高数据的查询效率。下列不利于提高系统查询效率的优化方案是
A.为经常出现在查询条件中的列建立索引
B.为频繁进行排序的列建立索引
C.将数据文件和日志文件分别放置在不同磁盘上
D.将表的数据和索引放置在同一磁盘上
文件管理方式本质上是把数据组织成( )的形式存储在磁盘上。
A. 文件
B. 表
C. 记录
D. 数据库
试题(58)
对于提升磁盘I/O性能问题,以下表述正确的是(58) 。
(58)
A.数据库对象在物理设备上的合理分布能改善系统读写性能
B.磁盘镜像可以提高磁盘读写的速度
C.建议把数据库、回滚段、日志放在同一块设备上,以提高数据读写的性能
D.将磁盘升级到更大容量可提高磁盘I/O速度
试题(58)分析
本题考查提升磁盘I/O的方法。
正确的概念是:
数据库对象在物理设备上的合理分布能改善系统读写性能。
不是所有的磁盘镜像都可以提高磁盘读写的速度。建议把数据库、回滚段、日志不要放在同一块设备上,以提高数据读写的性能。
将磁盘升级到更大容量并不能提高磁盘I/O速度。
参考答案
(58)A
A、数据表
B、工作簿
C、工作表
D、数据库
● 某公司的数据库应用系统中,其数据库服务器配置两块物理硬盘,可以采用下述存储策略:
1)将表和索引放在同一硬盘的不同逻辑分区以提高性能
2)将表和索引放在不同硬盘以提高性能
3)将日志文件和数据库文件放在同一硬盘的不同逻辑分区以提高性能
4)将日志文件和数据库文件放在不同硬盘以提高性能
5)将备份文件和日志文件与数据库文件放在同一硬盘以保证介质故障时能够恢复 一个比较正确合理的存储策略是 (57) 。